Données météorologiques et des transports, fichier des entreprises... les services publics rendent disponibles de plus en plus d'informations. Porteuse de promesses pour doper l'innovation et améliorer la transparence, l'ouverture des données publiques demeure désorganisée et freinée par des inquiétudes liées, notamment, au respect de la vie privée.
Au milieu des années 2000, Internet fait sa révolution. Fini le temps où les internautes n'étaient que de simples consommateurs de contenus en ligne : avec l'essor des blogs et des réseaux sociaux, ils discutent, partagent leurs trouvailles et se mettent à collaborer. Le Web 2.0 est né, l'économie numérique prend son envol, et de nouveaux sites interactifs voient le jour. Dans ce nouvel écosystème, un site singulier apparaît en 2005 aux États-Unis. Son nom ? Chicago Crimes. Il permet à tous les habitants de l'ancien fief d'Al Capone de géolocaliser tous les homicides, vols et agressions diffusés par la police de la ville depuis 1996. Pour ce faire, son créateur, Adrian Holovaty, a dû « hacker » les données des autorités. De fait, l'accès aux informations policières était restreint : celles-ci n'étaient disponibles que pour une période de deux semaines et leur classement, un brin désordonné, rendait toute réutilisation difficile.
Toutefois, ce site novateur a contribué à exposer au grand jour le potentiel de certaines données publiques, pour peu qu'on les croise avec d'autres jeux de données pertinents issus des sphères publiques ou privées. Ici, la possibilité d'évaluer le niveau de criminalité par quartier est susceptible d'en intéresser plus d'un... Les professionnels de l'immobilier ne pourraient-ils pas s'en servir pour justifier leurs prix et mieux informer leurs clients ? Quant à la police de Chicago, ne devrait-elle pas organiser ses patrouilles plus efficacement ?
Avec ce type d'applications, l'idée de mener une politique d'ouverture et de partage des données publiques auprès des citoyens - dite d'open data - s'est imposée tant pour doper l'innovation que pour améliorer les services de l'État. Pays pionniers en la matière, les États-Unis et le Royaume-Uni en ont fait une priorité dès la fin des années 2000. En France, Etalab, une mission interministérielle dédiée à l'open data, est née en décembre 2011 sous l'égide du Premier ministre. Elle répondait aussi à une demande toujours plus forte de transparence dans un contexte de défiance envers les pouvoirs publics.
Jusqu'à présent, Etalab a publié plus de 13.000 jeux de données sur son portail «data.gouv.fr ». Pêle-mêle, celles-ci concernent l'inventaire des lieux publics accessibles aux handicapés, la pollution atmosphérique, les prix à la vente des logements neufs, la localisation et la qualité des soins des établissements de santé ou la carte des accidents de la route... Ces informations, une fois croisées avec d'autres jeux de données, donnent ainsi naissance à de nombreux nouveaux services. Parmi eux, il y a KelQuartier.com. Né en 2010, ce site rassemble les données publiques de quelque 42.000 quartiers en France, et permet à l'internaute de trouver le meilleur endroit où s'installer. Ainsi, dans le quartier de Saint-Charles, à Marseille, on apprend que le revenu moyen est de 22.200 euros, qu'il y a en moyenne un commerçant tous les 20 mètres, ou encore que le taux de réussite au bac dans ses lycées est de 83%.
Un marché français encore balbutiant
Les groupes publics tirent aussi profit de l'ouverture de leurs données. C'est le cas de la SNCF. En juin 2013, au terme d'une collaboration avec une start-up, le géant du rail a lancé Tranquilien. Cette application permet aux voyageurs de consulter le taux de remplissage des trains sur le réseau Transilien et certaines lignes RER. Pour mettre au point cet outil, la société nationale a utilisé les données de trafic engrangées ces dernières années pour la gestion de son réseau. Une fois son trajet sélectionné dans l'application, un code couleur est appliqué à chaque train. S'il s'affiche en « vert », on y trouvera à coup sûr une place assise. Mais si le train est « rouge », il faudra sûrement faire le trajet debout dans une rame bondée. Toutefois, des précautions s'imposent.
« Nous pouvons partager toutes les données qui relèvent du service public, mais certains jeux doivent demeurer en interne », insiste un responsable de SNCF.
Pas question, par exemple, de divulguer les taux de remplissage de certains trains dont la concurrence pourrait faire son miel. Pour l'heure, la SNCF n'est pas en mesure de chiffrer les retombées économiques de l'open data. Et pour cause : de nombreuses sociétés et start-up réutilisent ses données sans que le groupe soit au courant. À la louche, « il y a environ 80% de réutilisations masquées », affirme notre responsable.
De fait, dresser l'inventaire des innovations liées à l'open data - et donc évaluer leur impact économique - relève du chemin de croix. Pour autant, les études sur la libération des données y voient toutes une véritable poule aux oeufs d'or dans les années à venir. En 2012, la Commission européenne a estimé que le marché de l'information publique pourrait bientôt atteindre les 140 milliards d'euros par an, contre 30 milliards actuellement. Plus récemment, l'institut McKinsey a livré des chiffres encore plus imposants.
Au milieu des années 2000, Internet fait sa révolution. Fini le temps où les internautes n'étaient que de simples consommateurs de contenus en ligne : avec l'essor des blogs et des réseaux sociaux, ils discutent, partagent leurs trouvailles et se mettent à collaborer. Le Web 2.0 est né, l'économie numérique prend son envol, et de nouveaux sites interactifs voient le jour. Dans ce nouvel écosystème, un site singulier apparaît en 2005 aux États-Unis. Son nom ? Chicago Crimes. Il permet à tous les habitants de l'ancien fief d'Al Capone de géolocaliser tous les homicides, vols et agressions diffusés par la police de la ville depuis 1996. Pour ce faire, son créateur, Adrian Holovaty, a dû « hacker » les données des autorités. De fait, l'accès aux informations policières était restreint : celles-ci n'étaient disponibles que pour une période de deux semaines et leur classement, un brin désordonné, rendait toute réutilisation difficile.
Toutefois, ce site novateur a contribué à exposer au grand jour le potentiel de certaines données publiques, pour peu qu'on les croise avec d'autres jeux de données pertinents issus des sphères publiques ou privées. Ici, la possibilité d'évaluer le niveau de criminalité par quartier est susceptible d'en intéresser plus d'un... Les professionnels de l'immobilier ne pourraient-ils pas s'en servir pour justifier leurs prix et mieux informer leurs clients ? Quant à la police de Chicago, ne devrait-elle pas organiser ses patrouilles plus efficacement ?
Avec ce type d'applications, l'idée de mener une politique d'ouverture et de partage des données publiques auprès des citoyens - dite d'open data - s'est imposée tant pour doper l'innovation que pour améliorer les services de l'État. Pays pionniers en la matière, les États-Unis et le Royaume-Uni en ont fait une priorité dès la fin des années 2000. En France, Etalab, une mission interministérielle dédiée à l'open data, est née en décembre 2011 sous l'égide du Premier ministre. Elle répondait aussi à une demande toujours plus forte de transparence dans un contexte de défiance envers les pouvoirs publics.
Jusqu'à présent, Etalab a publié plus de 13.000 jeux de données sur son portail «data.gouv.fr ». Pêle-mêle, celles-ci concernent l'inventaire des lieux publics accessibles aux handicapés, la pollution atmosphérique, les prix à la vente des logements neufs, la localisation et la qualité des soins des établissements de santé ou la carte des accidents de la route... Ces informations, une fois croisées avec d'autres jeux de données, donnent ainsi naissance à de nombreux nouveaux services. Parmi eux, il y a KelQuartier.com. Né en 2010, ce site rassemble les données publiques de quelque 42.000 quartiers en France, et permet à l'internaute de trouver le meilleur endroit où s'installer. Ainsi, dans le quartier de Saint-Charles, à Marseille, on apprend que le revenu moyen est de 22.200 euros, qu'il y a en moyenne un commerçant tous les 20 mètres, ou encore que le taux de réussite au bac dans ses lycées est de 83%.
Un marché français encore balbutiant
Les groupes publics tirent aussi profit de l'ouverture de leurs données. C'est le cas de la SNCF. En juin 2013, au terme d'une collaboration avec une start-up, le géant du rail a lancé Tranquilien. Cette application permet aux voyageurs de consulter le taux de remplissage des trains sur le réseau Transilien et certaines lignes RER. Pour mettre au point cet outil, la société nationale a utilisé les données de trafic engrangées ces dernières années pour la gestion de son réseau. Une fois son trajet sélectionné dans l'application, un code couleur est appliqué à chaque train. S'il s'affiche en « vert », on y trouvera à coup sûr une place assise. Mais si le train est « rouge », il faudra sûrement faire le trajet debout dans une rame bondée. Toutefois, des précautions s'imposent.
« Nous pouvons partager toutes les données qui relèvent du service public, mais certains jeux doivent demeurer en interne », insiste un responsable de SNCF.
Pas question, par exemple, de divulguer les taux de remplissage de certains trains dont la concurrence pourrait faire son miel. Pour l'heure, la SNCF n'est pas en mesure de chiffrer les retombées économiques de l'open data. Et pour cause : de nombreuses sociétés et start-up réutilisent ses données sans que le groupe soit au courant. À la louche, « il y a environ 80% de réutilisations masquées », affirme notre responsable.
De fait, dresser l'inventaire des innovations liées à l'open data - et donc évaluer leur impact économique - relève du chemin de croix. Pour autant, les études sur la libération des données y voient toutes une véritable poule aux oeufs d'or dans les années à venir. En 2012, la Commission européenne a estimé que le marché de l'information publique pourrait bientôt atteindre les 140 milliards d'euros par an, contre 30 milliards actuellement. Plus récemment, l'institut McKinsey a livré des chiffres encore plus imposants.
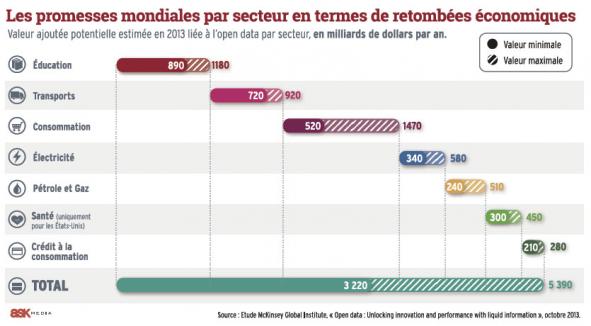
D'après une étude d'octobre 2013, les retombées économiques en termes de services nouveaux et de gains de productivité s'établiraient entre 3200 et 5 400 milliards de dollars dans le monde dans sept secteurs clés, dont l'éducation, les transports et les produits de consommation. Un fabuleux gâteau dont la part de l'Europe s'élèverait à environ 900 milliards de dollars, contre 1 100 milliards pour les États-Unis, et 1 700 milliards pour le reste du monde.
Pour la France, le marché en est encore à ses balbutiements. Il y a deux ans, la société Serda, spécialiste en systèmes d'information, estimait que les retombées économiques avoisinaient les 740 millions d'euros en 2011. Un montant honorable, mais qui s'avère encore bien éloigné des prévisions de Bruxelles.
De fait, peu d'applications créées à partir de données publiques deviennent rentables. En libérant des données telles que la liste des hôtels, des restaurants, des activités culturelles ou l'emplacement des offices de tourisme, les Bouches-du-Rhône, le Var et les Alpes-Maritimes espéraient des retombées concrètes en termes d'image ou de fréquentation. Mais les services créés par une poignée d'entrepreneurs chevronnés peinent à trouver leur public. Ainsi, MyProvence Agenda, le plus gros succès parmi les 17 applications du site data.visitprovence.com, a été seulement téléchargé moins de 5.000 fois. D'autres, à l'image de ParkIn 13, qui recense depuis janvier 2013 toutes les places de parking de Marseille, totalisent « entre 50 et 100 » utilisateurs... Une douche froide pour les entrepreneurs.
Des données ouvertes... mais payantes
Ce phénomène s'explique en partie par la jeunesse du mouvement.
« L'open data n'est pas encore entré dans les moeurs, il reste peu connu et peu compris du grand public », décrypte Claire Gallon, la co-créatrice de l'association LiberTic.
Autre problème : les spécialistes estiment que seulement 10% à 20% des données publiques sont accessibles... Certes, la politique volontariste de l'État depuis 2011 a permis de lever quelques freins. Et la future loi numérique imposera l'obligation de libérer gratuitement les nouvelles données. Mais de nombreuses administrations freinent toujours des quatre fers. Les difficultés sont à la fois techniques (manque de logiciels adaptés), financières (libérer les données représente un investissement humain et matériel), et psychologiques.
« La culture du secret est très ancrée au sein de l'administration. Ouvrir les données sans savoir par qui et comment elles vont être réutilisées, c'est une révolution », explique Henri Verdier, le directeur d'Etalab.
Face à la désorganisation générale, les réutilisateurs s'arrachent les cheveux.
« On trouve des données dans tous les formats, elles sont parfois difficiles d'accès, incomplètes, datées ou illisibles... », soupire Denis Berthault, qui compile, croise, analyse et vend des données juridiques pour la société Lexis Nexis.
Autre exemple, l'Institut national de l'information géographique et forestière (IGN) a bien « ouvert » quelques cartes... mais leur faible résolution complique leur réutilisation.
Pour créer un véritable écosystème de l'open data en France, il faudra donc améliorer l'accès aux données. Des informations d'intérêt économique et utiles à l'expression de la démocratie ne sont toujours pas disponibles, à l'image des données postales ou du détail des dépenses publiques. Parmi les jeux de données ouverts, certains restent soumis à des redevances. Ainsi, il faut payer jusqu'à plusieurs dizaines de milliers d'euros pour accéder aux données de l'Insee, de Météo France, de l'IGN, au fichier Sirene des entreprises, aux données immobilières ou même aux prix des carburants ! Un frein insurmontable pour les citoyens et les entrepreneurs.
Comment protéger la confidentialité ?
Cette situation tend même à relativiser les performances de la France. En 2013, l'Open Knowledge Foundation a publié un classement de 70 pays en fonction de l'accès des citoyens aux données publiques. Pénalisé par l'indisponibilité et la cherté de données stratégiques, l'Hexagone terminait en seizième position, loin derrière le Royaume-Uni (premier), les États-Unis (deuxième), et même... la Bulgarie et la Moldavie.
Conscient de ce problème, le magistrat de la Cour des comptes, Mohammed Adnène Trojette, remettait en question, dans un rapport remis en novembre 2013, l'utilité des redevances. En 2012, elles ne rapportaient « que » 34,7 millions d'euros à l'État, dont près de 5 millions provenaient... des acheteurs publics eux-mêmes ! De nombreux acteurs (LiberTic, Regards citoyens...) prônent leur suppression pure et simple. D'autres, à l'image du Groupement français de l'industrie de l'information (GFII), soulignent la qualité des données soumises à redevance et l'utilité de ces dernières pour financer la politique d'open data. Dans un premier temps, la solution pourrait consister à ouvrir, gratuitement, des données considérées comme stratégiques. Ainsi, le GFII, qui s'apparente au « lobby » des entreprises du secteur privé, vient de soumettre à Etalab une liste de « données pivots » (adresses et noms des lieux publics, données des transports, limites des communes, zones de compétence administrative...) jugées indispensables au développement d'un « Web de données ».
« C'est évidemment essentiel », confirme le directeur d'Etalab.
Preuve que la société doit encore mûrir sur les questions d'open data, le spectre de la violation de la vie privée s'invite régulièrement dans le débat public. Doit-on ouvrir toutes les données, y compris celles relatives à la santé ? Peut-on empêcher toute réutilisation préjudiciable aux citoyens ? Les avis divergent. Aucun grand scandale autour des données n'a éclaté jusqu'à présent. Mais c'est aussi parce que la loi Informatique et liberté du 6 janvier 1978 veille scrupuleusement au respect de la vie privée. Cette législation est-elle un frein ? Scandalisé par l'affaire du Médiator, le collectif Initiative transparence santé (ITS) donne de la voix pour réclamer l'ouverture des données de santé.
Selon ITS, les 1,2 milliard de feuilles de soins enregistrées et stockées dans le Système national d'information interrégimes de l'Assurance maladie (Sniiram) pourraient se révéler très utiles pour mieux connaître la santé des Français, adapter la politique de l'État, faire des économies et repérer les abus, à l'image des prescriptions inadaptées du Médiator. D'autres mettent en garde contre l'ouverture d'une boîte de Pandore.
« Utiliser les données de santé tout en protégeant la confidentialité apparaît contradictoire ou difficile à concilier », résume l'inspecteur général des affaires sociales, Pierre-Louis Bras, dans un rapport remis fin 2013 à la ministre de la Santé, Marisol Touraine.
L'histoire semble se diriger vers davantage d'ouverture. Pour la première fois, le Conseil d'État a validé, fin mai, la démarche de la PME bretonne, Celtipharm, qui exploite des feuilles de soins électroniques dans un but épidémiologique. Les magistrats ont jugé que cette utilisation de données privées ne viole pas les principes de la loi de 1978.
« Nous sommes en pleine transition. Le paysage de l'open data a déjà beaucoup évolué et sera très différent dans trois ans », pronostique Henri Verdier.
L'enjeu est démocratique, économique, social et stratégique. À l'heure du redressement productif, l'open data pourrait se révéler une carte maîtresse pour créer une véritable industrie numérique française.
source : La Tribune